INTELIPS
LLM-labeled email-priority NLP
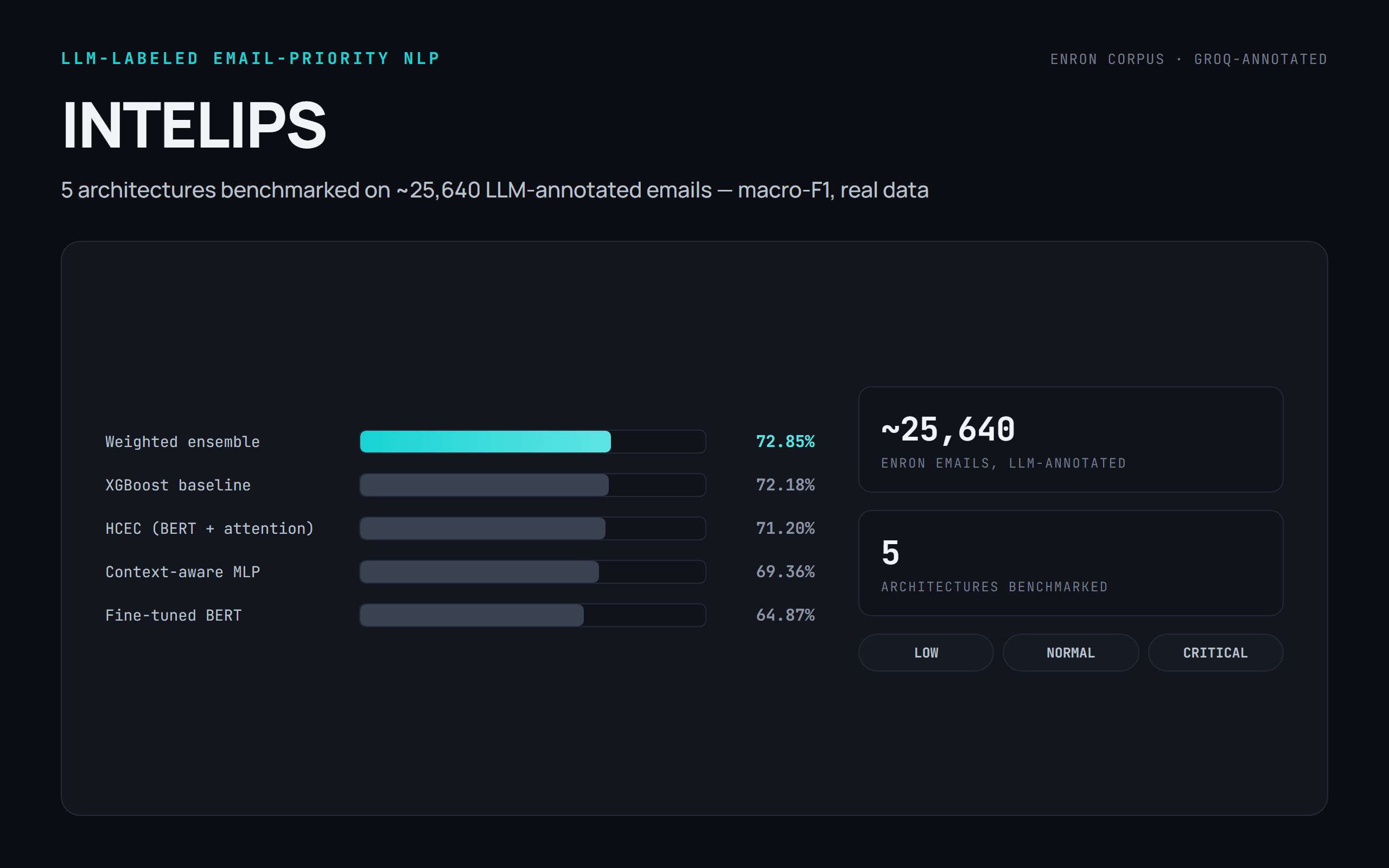
Auto-labels 25,640 Enron emails with an LLM, then benchmarks five architectures. A weighted ensemble tops out at 72.85% macro-F1 on the real annotated data.
- CFOURGENT: wire approval needed before 3pm
- CalendarReminder: standup in 15 minutes
- Newsletter10 productivity hacks for 2026
- ClientRe: contract, one blocking question
- GitHubYour weekly digest
Synthetic inbox, scored by urgency + intent.
Try the priority classifier on sample messages.
INTELIPS builds an email-prioritization pipeline on the Enron corpus. An open-weights LLM served through the Groq API first auto-labels ~25,640 emails into three priority levels, then five models are trained and compared in PyTorch / scikit-learn / XGBoost: a TF-IDF + metadata XGBoost baseline, a context-aware MLP, a BERT + multi-head-attention model, a fine-tuned BERT, and PAEPS, a network that adds a learned per-user embedding. On the real LLM-annotated data the traditional XGBoost baseline reaches 72.18% macro-F1 and a weighted ensemble edges ahead at 72.85%; the personalization layer is an exploratory proof-of-concept, evaluated on synthetic personas. SHAP/LIME attribute the signal. Delivered as notebooks plus standalone training scripts.
- Python
- PyTorch
- scikit-learn
- XGBoost
- BERT / Transformers
- Groq API (LLM)
- SHAP
- Jupyter
Architecture · LLM labels → five-model benchmark
LLM auto-labeling
An open-weights LLM (served via the Groq API) labels ~25,640 Enron emails into Low / Normal / Critical priority.
Five-model benchmark
TF-IDF + metadata XGBoost, a context-aware MLP, BERT + multi-head attention, fine-tuned BERT, and a per-user-embedding net (PAEPS), all trained and compared.
Best on real data
A weighted ensemble reaches 72.85% macro-F1, just past the 72.18% XGBoost baseline. The spread between models is small.
Attribution
SHAP / LIME attribute which features drive each priority call.
- Best real-data F1
- 72.85% (ensemble)
- XGBoost baseline
- 72.18% macro-F1
- LLM-annotated emails
- 25,640 (Enron)
- Models benchmarked
- 5
What I'd improve
The spread between models is tiny (72.18% → 72.85%), so the next lever isn't a bigger network. It's label quality: a human-audited gold set to measure and de-noise the LLM annotations, plus calibrated priority thresholds.